2.9. 字库生成工具使用
该工具的作用是根据ttf生成对应.PIX和.TAB文件,用于杰理ui框架和推屏的文字显示,可裁剪,可改字体,可换字号。 其中FontTool.exe会根据font.xml文件的配置进行采集,在font.xml可以配置对应代码页使用的ttf文件以及每个代码页中需要提取字符的范围,故可以理解为.xml文件即FontTool.exe的配置, 可以通过修改.xml文件来达到修改FontTool.exe提取范围的效果。工具流程图如下:
从用户角度来看,通过修改font.xml可以裁剪出自己需要的国家的语言,而通过修改charset路径下的.xml文件可以进一步修改对应国家语言的字符范围。
2.9.1. 文件结构说明
2.9.1.1. charset文件夹
charset文件夹中存放了多个代码页的.xml文件,可以通过修改.xml文件里的编码范围来进行裁剪。 示例:在ascii.xml文件中,编码范围如下:
裁剪一半,改成如上图所示,那么不在xml文件里的编码,工具就不会去采集对应的字符,生成的字模文件大小自然就减小了。在charset路径下的.xml文件的字符编码范围可以重复,工具会自动去重。
2.9.1.2. Fonts文件夹
Fonts文件夹中存放常用的ttf文件,即字体文件,可以通过更换ttf文件来修改字体,后面若是要新加字体文件,就存放在该文件夹。
2.9.1.3. Codepage文件夹
在Codepage.txt文件中,用户可以根据该文件找到对应语言的代码页,保留需要用的上的语言,用不上的就在font.xml中去删掉,从而进行代码页裁剪。 对于在Codepage.txt中找不到的语言,可以先自行上网搜索该语言使用的字符,是否在常用的代码页里面,如果在常用代码页里面,则可以选取对应代码页去生成.PIX进行显示。
2.9.1.4. font.xml文件
字库生成工具会根据该font.xml文件的配置去采集对应字模,可以通过修改改文件去控制字模的采集,如代码页裁剪、更换ttf字体文件等
默认ttf:font.xml文件中第4行中的Sun-ExtA.ttf为默认ttf,也就是下面big5,gb2312,gbk,ksc和sjis用到的ttf;
可选代码页:可以根据上面的代码页进行删减从而实现字库裁剪;
字体宽高设置:fix为固定宽高,多用于中日韩字符;valid为截取有效部分,多用于印地语,泰语和藏语;variable为可变,对于这部分设置不建议随意修改;
ttf配置:可以给对应代码页配置特定的字体,只需要在对应代码页中更换目录下自行添加的ttf即可。
Tips: 更新完font.xml配置后,尽量重启一下FontTool.exe,防止配置没有生效。
2.9.1.5. FontTool.exe
字模提取工具,具体按钮功能如下:
选择字体:设置默认 TTF 文件(适用于 big5、gb2312、gbk、ksc、sjis 代码页)。这里选取的ttf直接应用于简体中文、繁体中文、日语和韩语。若想要修改指定代码页的ttf,可以在Font.xml中进行修改。
采集字模:采集当前选择的代码页的字模,如unicode V2就是采集unicode字库的.PIX文件,而ANSI采集的是F_ASCII.PIX,即ascii.res,是数字控件,文字控件的内置字库;
全部采集:无视当前选择代码页,将所有代码页的字模提取到.PIX,.TAB文件中;
字体大小:可以设置字模字号,如上图为设置24字号;
粗体/斜体/固定宽度:可根据需求进行勾选,从而提取对应需求的字模;
位深度(SDK 220后新增):每像素所占位数,该值越高,字体抗锯齿效果越好,但占用空间也会增大;
字符预览:如下图所示
“啊”字符的unicode编码为0000554a,在红色框框中输入554a即可出现“啊”的预览。
注意:目前只支持unicode字库的裁剪,也就是代码页选择unicode V2时才能裁剪。
2.9.2. 应用示例
下面以只需要全简体中文为例,做一个简单的裁剪示例:
打开Codepage.txt文件,找到全简体中文
找到对应的代码页是gbk,那么在配置文件font.xml中,就只需要保留gbk即可。这里gbk选择的字体会使用到默认字体(前面介绍有提到)。
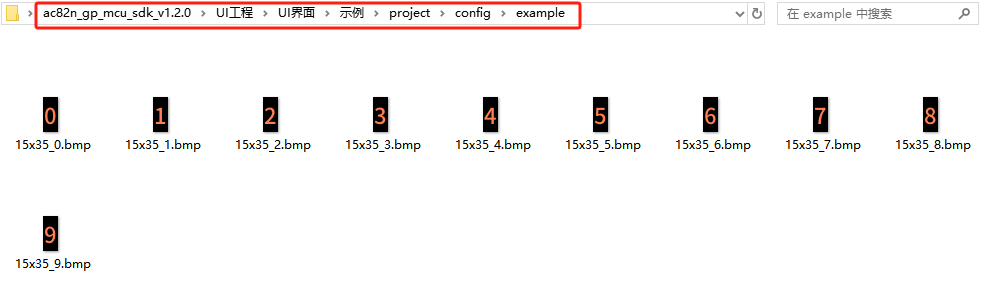
ascii为公共字库,包含了ascii码表中的内容,建议保留。 如果并不需要全简体中文的所有字符,可以打开charset文件夹,找到gbk.xml进行二次裁剪。 配置结束后,打开FontTool.exe,设置相应字号,这里以字号24为例,采集unicode字库,故代码页设置unicode V2,点击“采集字模”,等待裁剪即可。
采集结束后会出现弹窗,并生成对应.PIX到当前路径下:
采集结束后需要修改字库文件名称,公版unicode字库的.PIX文件默认为F_UNIC_ALL.PIX,故在这里将F_UNIC.PIX.Sun-ExtA.24重命名为F_UNIC_ALL.PIX即可。 若有其他需求也可以修改为其他名字,在font_textout.c中匹配上即可,但需要注意名字长度有要求,不能超过15bytes,否则无法下载到flash。 至于采集其他代码页,以1252为例,选中1252 拉丁文后,点击采集字模:
最终生成的文件,将.PIX的后缀去掉,更改为F_CP1252.PIX即可。若需要用到生成的.PIX文件和.TAB文件,并在批处理添加上相应文件。